High performance computer system
Abstract
A parallel processor comprised of a plurality of processing nodes (10), each node including a processor (100-114) and a memory (116). Each processor includes means (100, 102) for executing instructions, logic means (114) connected to the memory for interfacing the processor with the memory and means (112) for internode communication. The internode communication means (112) connect the nodes to form a first array (8) of order n having a hypercube topology. A second array (21) of order n having nodes (22) connected together in a hypercube topology is interconnected with the first array to form an order n+l array. The order n+l array is made up of the first and second arrays of order n, such that a parallel processor system may be structured with any number of processors that is a power of two. A set of I/O processors (24) are connected to the nodes of the arrays (8, 21) by means of I/O channels (106). The means for internode communication (112) comprises a serial data channel driven by a clock that is common to all of the nodes. Images (17)
Classifications G06F15/17343
Direct connection machines, e.g. completely connected computers, point to point communication networks wherein the interconnection is dynamically configurable, e.g. having loosely coupled nearest neighbor architecture
US5113523A United States
Inventors
- Stephen R. Colley
- David W. Jurasek
- John F. Palmer
- William S. Richardson
- Doran K. Wilde
Current Assignee Arris Enterprises LLC
Worldwide applications
- 1985 US 1986 DE DE EP Application US06/731,170
Events
- 1985-05-06 Application filed by nCube Corp
- 1985-05-06 Priority to US06/731,170
- 1992-05-12 Publication of US5113523A
- 1992-05-12 Application granted
- 2009-05-12 Anticipated expiration
- 2019-02-22 Application status is Expired - Lifetime
BACKGROUND OF THE INVENTION
Field of the Invention
The invention relates to data-processing systems, and more particularly, to a high-performance, parallel-processing system.
Description of the Prior Art
In the past, data-processing systems utilizing parallel processing have met with limited commercial success. Consider, for example, the Illiac IV, designed by Burroughs Corporation. The Illiac IV utilizes an array of 64 processors, each with a local memory, operating in parallel with each processor executing the same instruction. This is known as a single-instruction-stream multiple data stream (SIMD) system. The Illiac IV is a very powerful computer and has been used to solve difficult scientific problems such as those involving fluid flow. The Illiac IV system is difficult to program because of the SIMD architecture. A more important disadvantage, however, is that the system lacks reliability. The mean time to failure is measured in hours.
Other parallel systems have been built for specific applications and would not be useful in more general, scientific applications. The high-performance data-processing systems that have been successful fall within one of two categories. The first category are those that are very high-speed uniprocessors that are heavily pipelined. The second category are special-purpose, inexpensive array processors that off-load data from a general processor for scientific processing. The Cray 1 and Cyber 205 fall within the first category, and the Floating-Point Systems’ AP-120 falls within the second category.
These prior systems have several disadvantages. For example, the Cray 1 system approaches the limits imposed by physical constants. Wires must be kept short and the processor must be tuned to get full performance. Programs must be vectorized to take advantage of the pipeline structure. If this is not done, the Cray 1 will run much slower than its maximum speed. Finally, because of its size and sensitivity, the Cray 1 requires expensive, special handling such as reinforced floors, liquid cooling, and hand tuning.
The second category of prior systems (array-processors) is also subject to the physical limits imposed by the speed of the single or small number of processors that make up the array.
Current attempts to utilize the multiple-instruction stream, multiple-data-stream (MIMD) approach to parallel processing runs into two significant problems. The first is that by using standard ECL circuits, the size of the system is limited by reliability constraints, and therefore such a system would not be operable with tens or hundreds of processors. The second problem is that current systems use a single memory shared by all the processors. This has the advantage of allowing a programmer to keep all of the data in one memory, but has a major disadvantage of limiting the system performance to the bandwidth of a single computer system.
It is a primary object of the present invention to provide a new data-processing architecture and apparatus utilizing parallel processing, with a system performance that is above the level of modern supercomputers, but is within the price range of a small mainframe computer.
BRIEF SUMMARY OF THE INVENTION
Briefly, the above object is accomplished in accordance with an embodiment of the present invention as follows. A data-processing architecture and implementation thereof is provided in which an array of processors having local memory are interconnected in a hypercube topology. Each of the processors includes means for executing instructions, logic means for interfacing the processor with its local memory, and means for communicating with other processors in the array.
By fabricating on a single chip serial communication channels, memory interfacing logic, and all CPU functions including high-speed, double-precision floating-point arithmetic, the component count is reduced to a minimum, thus reducing size and increasing the reliability of the system.
By using arrays of processors with local memory, physical limits imposed on a single processor, or single memory system, are avoided and performance can thus the increased by simply adding processing nodes.
A unique advantage flows from utilizing the hypercube topology, which consists of interconnecting all corners of an N-dimensional cube. Since the number of interconnections per processor grows as Log2(N), the distance across an array only grows as Log2(N). The number of interconnections in a prior art array grows as SQRT(N). Thus, random communication between nodes is much faster on a hypercube than on any array using a fixed number of interconnections per node.
The hypercube is a recursive array since an (N+1)-dimensional array is constructed by interconnecting two N-dimensional arrays. This makes it easy to partition a large array into smaller arrays for multitasking. Furthermore, since a small array is logically equivalent to a larger one, software can be written to run on any size array. This allows for very effective multitasking without programming overhead for task switching. This also results in highly reliable systems that gracefully degrade in the event of processor failures.
Almost all high-performance systems suffer from being I/O bound; that is, they compute so fast that moving data into and out of the system causes a bottleneck. In the present invention, the I/O bind is alleviated by including an extra serial channel on each processor to handle system I/O. Tis structure results in a very high I/O bandwidth and improved fault-tolerance. Since each node is accessible through the I/O system, even if several processors fail the remaining processors can be logically reconfigured into an operational array.
BRIEF DESCRIPTION OF THE DRAWINGS
The foregoing and other objects, features, and advantages of the invention will be apparent from the following detailed description of a preferred embodiment of the invention, as illustrated in the accompanying drawings wherein:
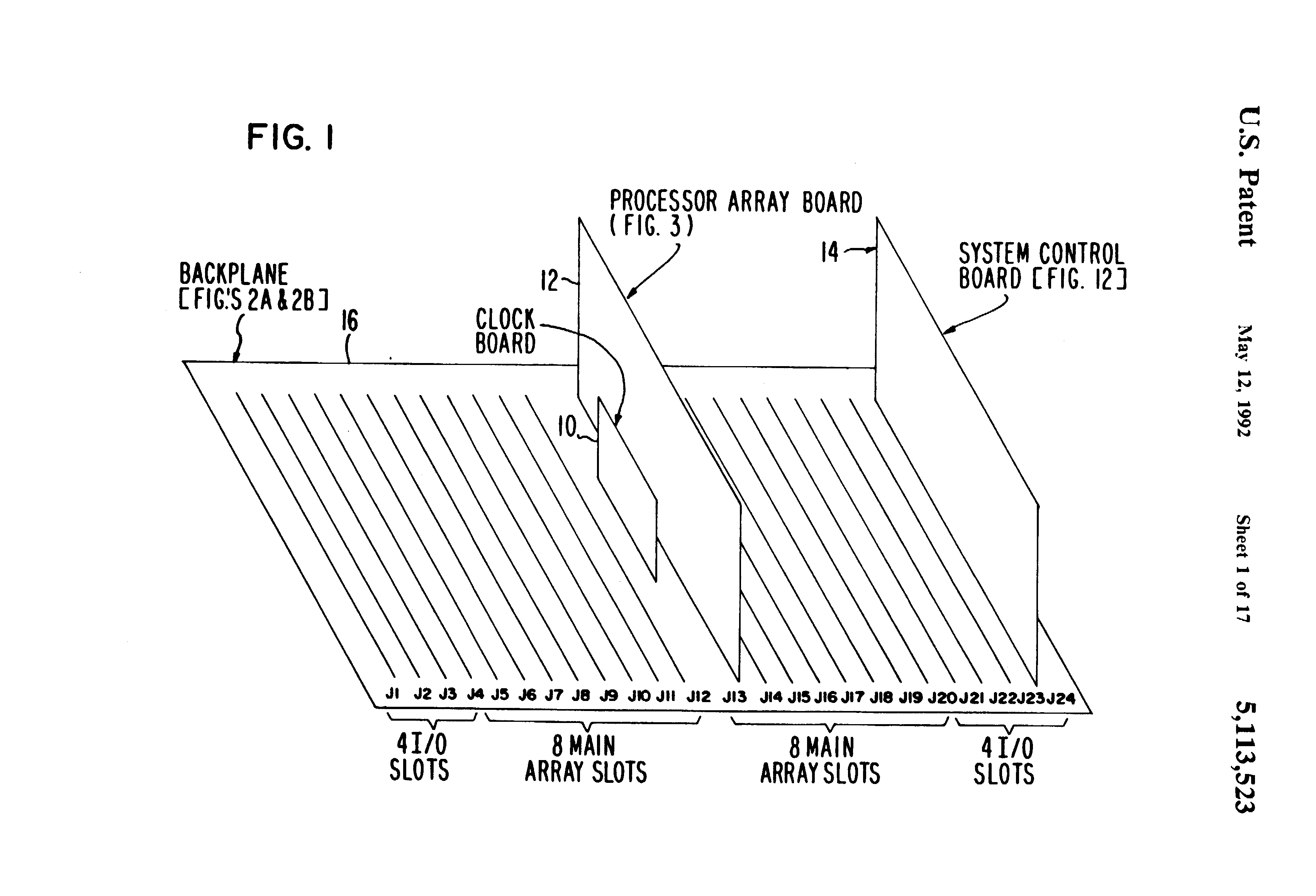
Fig 1 is a block diagram of a multiprocessing system in which the present invention is embodied;
{kind=link}
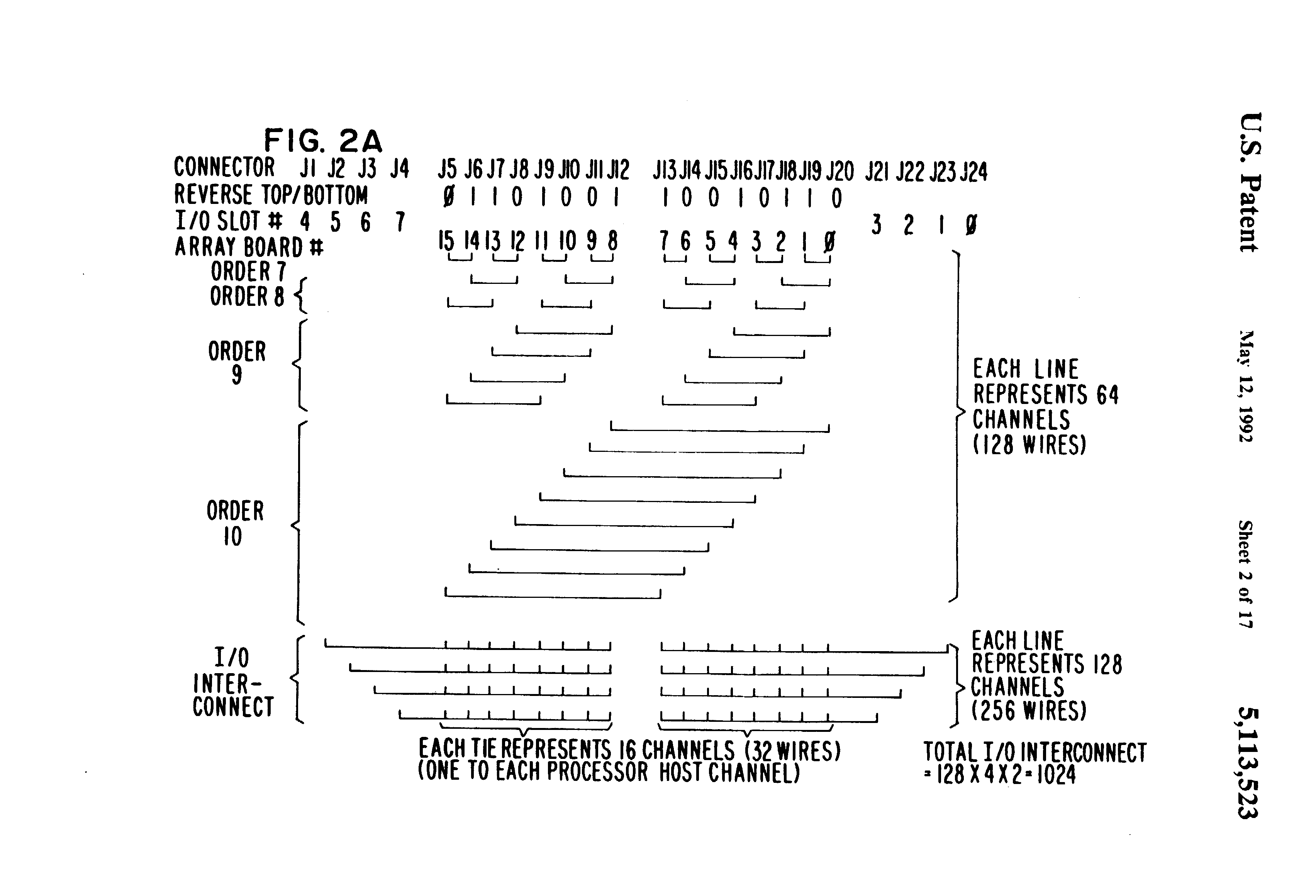
Fig 2a is a detailed diagram of the arrangement of the serial communications interconnect on the backplane of the multiprocessing system shown in FIG. 1;
{kind=link}
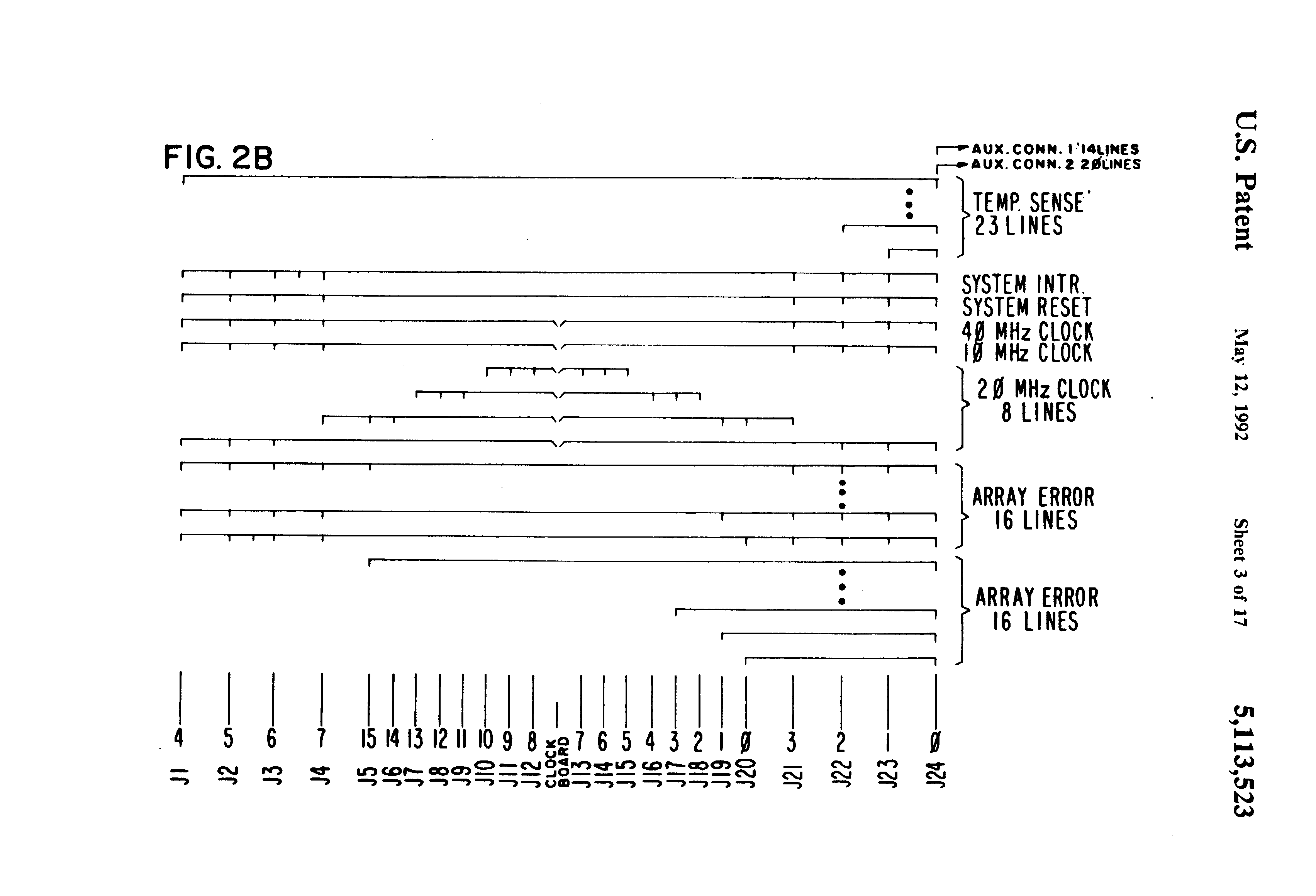
Fig 2b is a detailed diagram of the signal control interconnect on the backplane of the multiprocessing system shown in FIG. 1;
{kind=link}
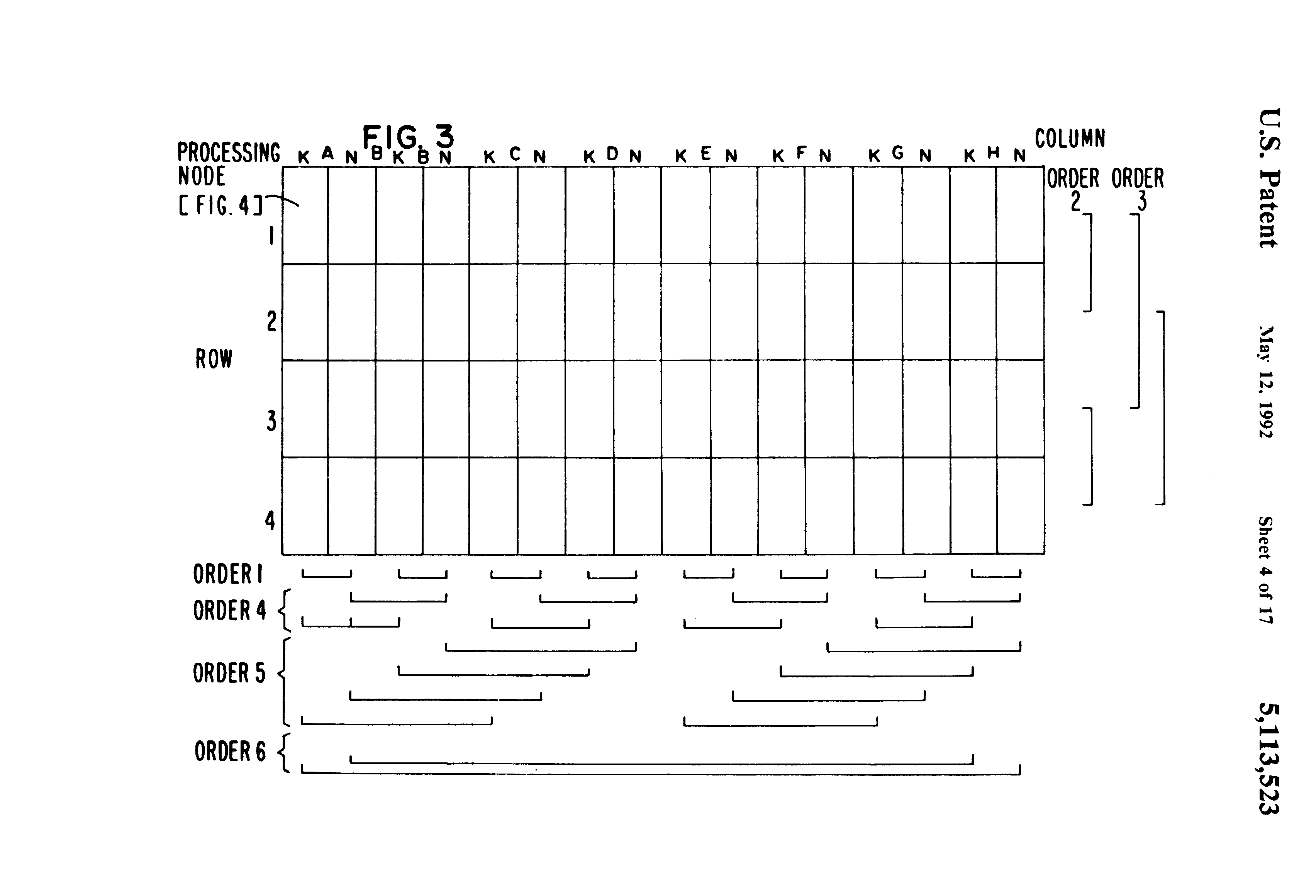
Fig 3 is a detailed diagram of the arrangement of processing nodes and serial communications interconnect on the processor array board shown in FIG. 1;
{kind=link}
Fig 4 is a detailed block diagram of a single processing node on the processor array board of FIG. 3;
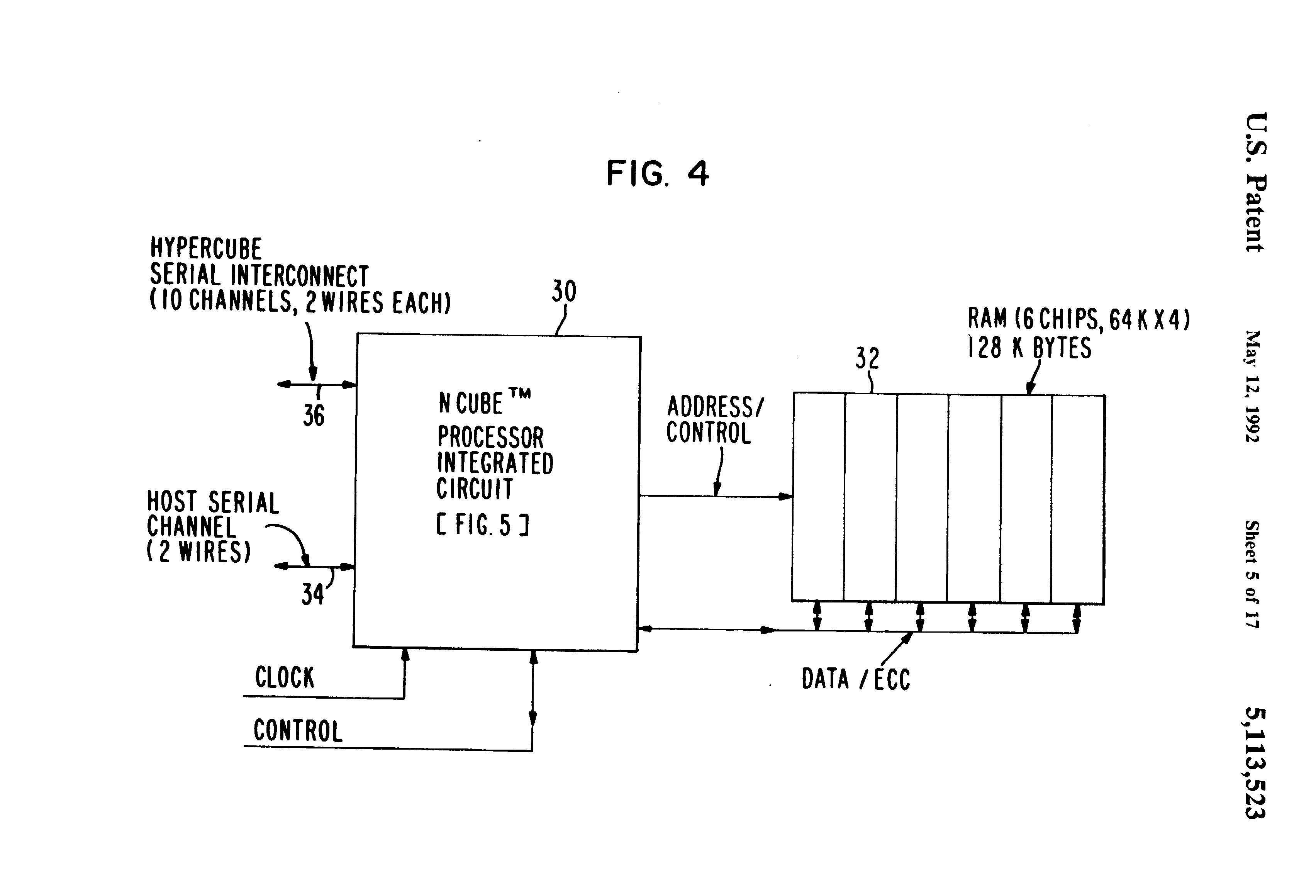{kind=link}
Fig 5 is a detailed block diagram of the Ncub™ processor integrated circuit shown in FIG. 4;
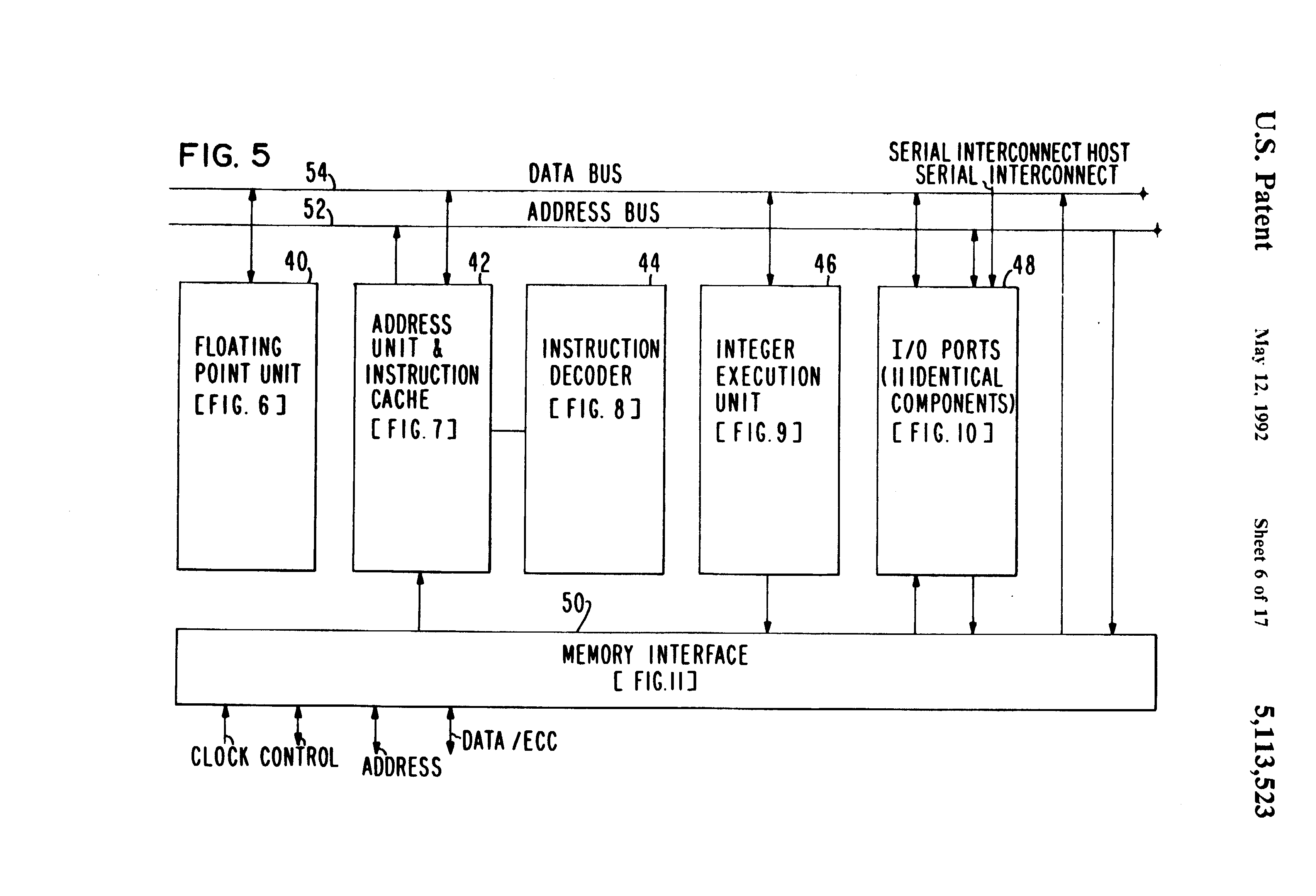{kind=link}
Fig 6 is a detailed block diagram of the floating point unit shown in FIG. 5;
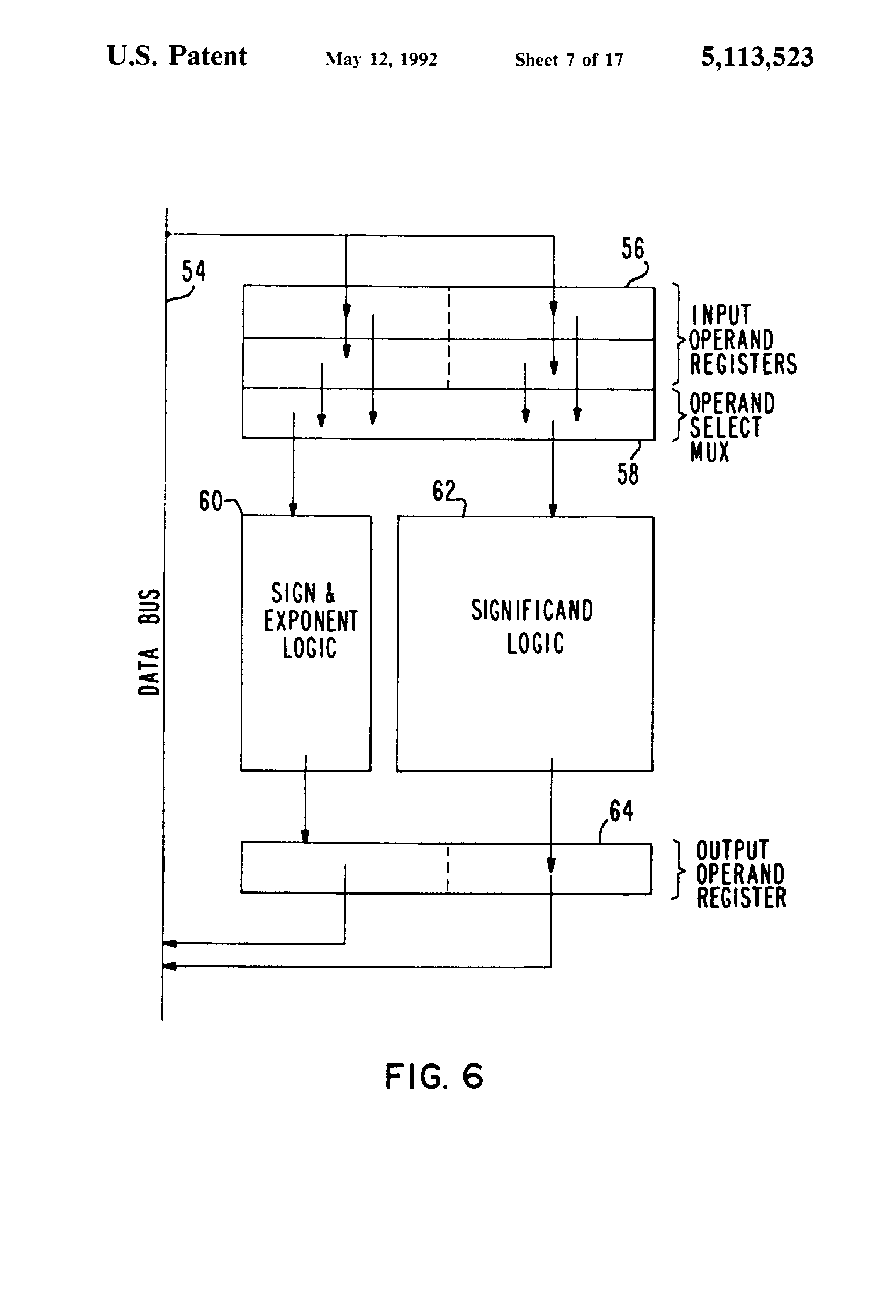{kind=link}
Fig 7 FIG. 7 is a detailed block diagram of the address unit and instruction cache shown in FIG. 5;
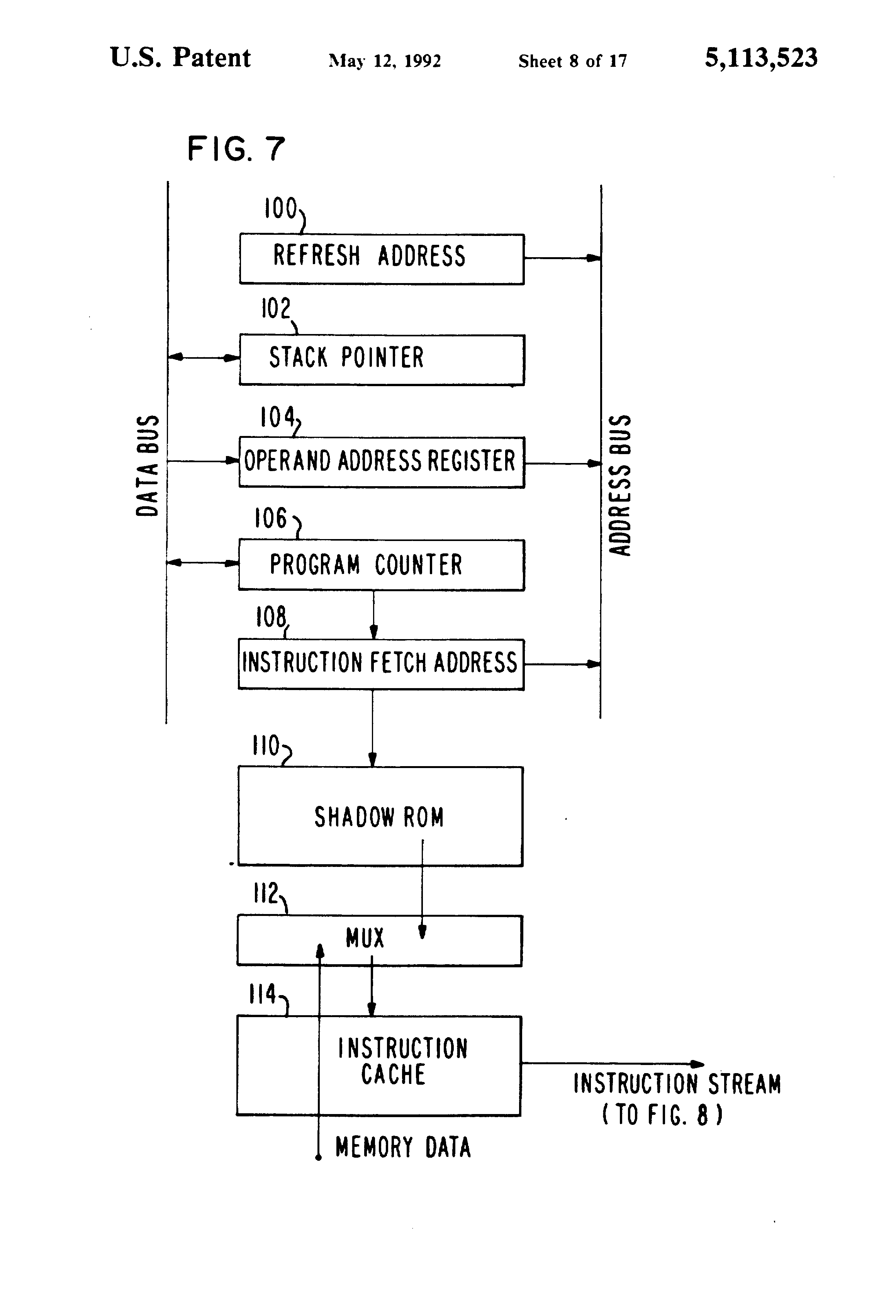{kind=link}
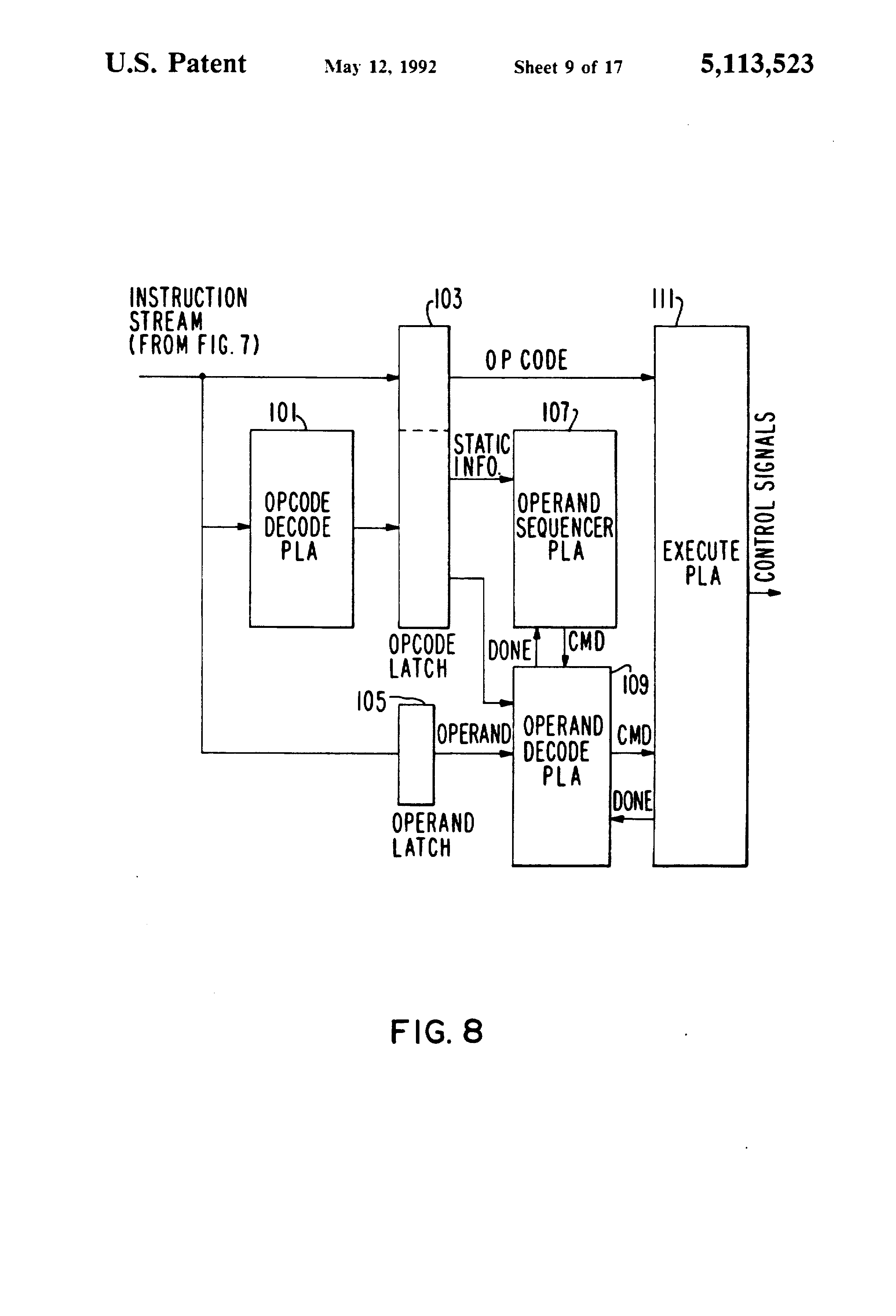
Fig 8 is a detailed block diagram of the instruction decoder shown in FIG. 5;
{kind=link}
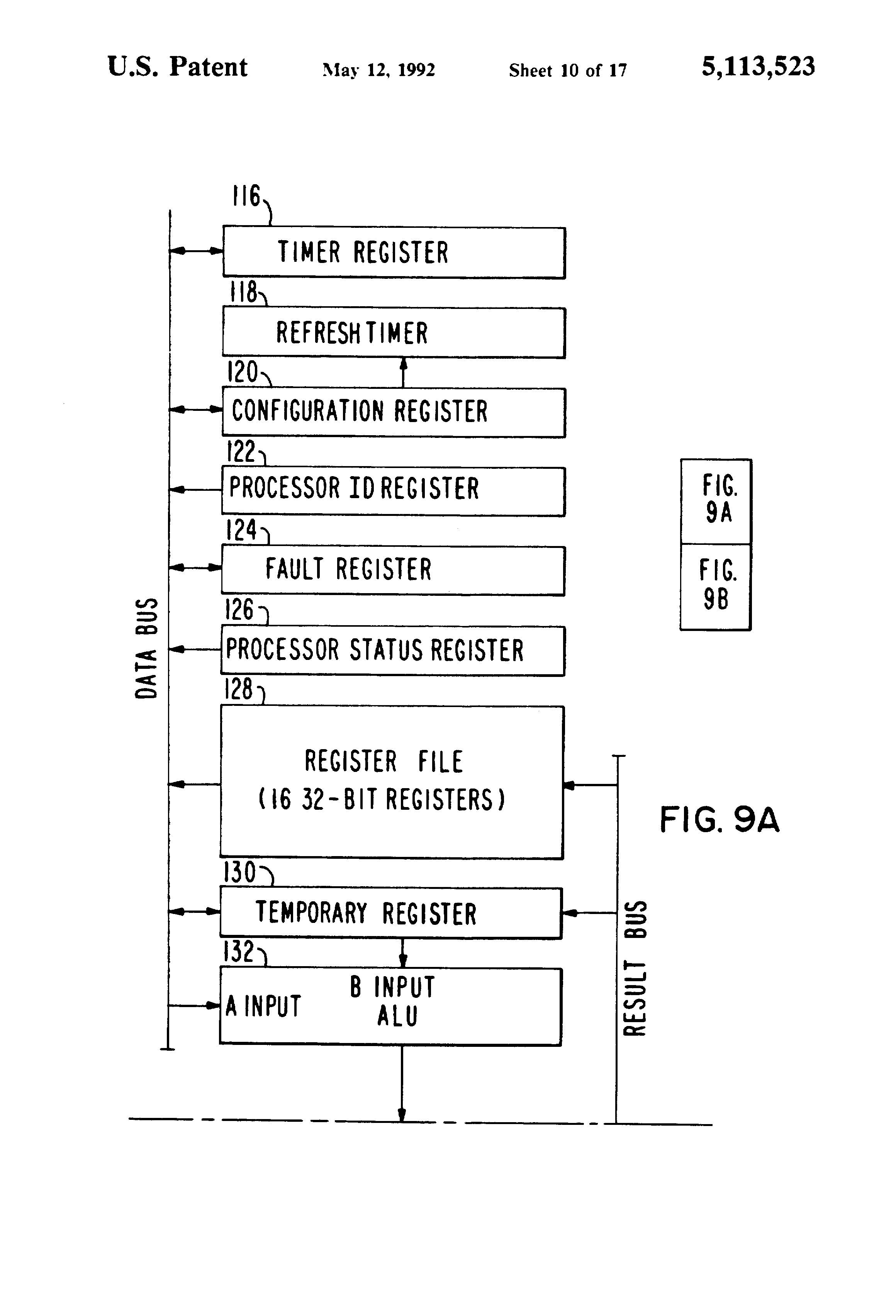
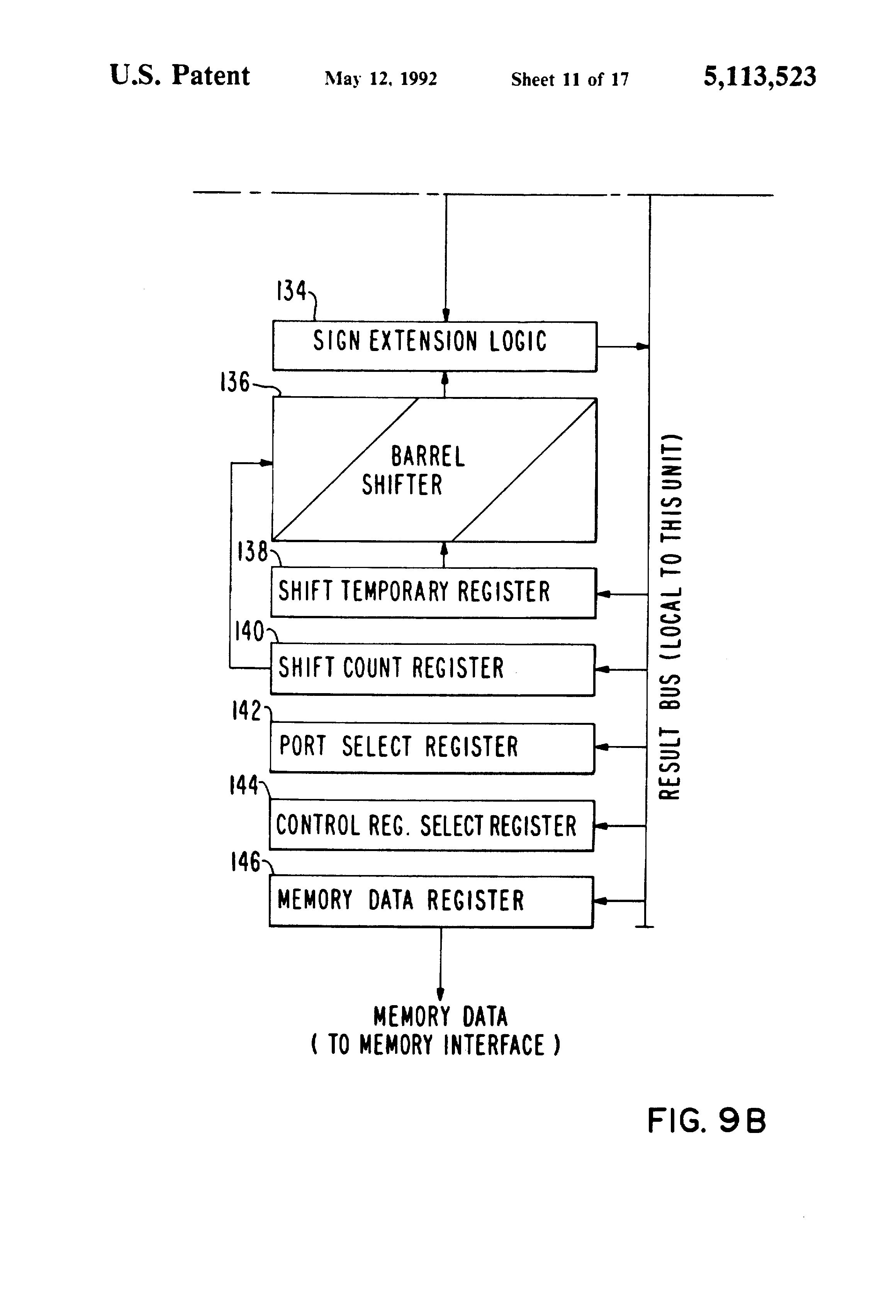
Fig 9a and Fig 9b together is a detailed block diagram of the integer execution unit shown in FIG. 5;
{kind=link}
{kind=link}
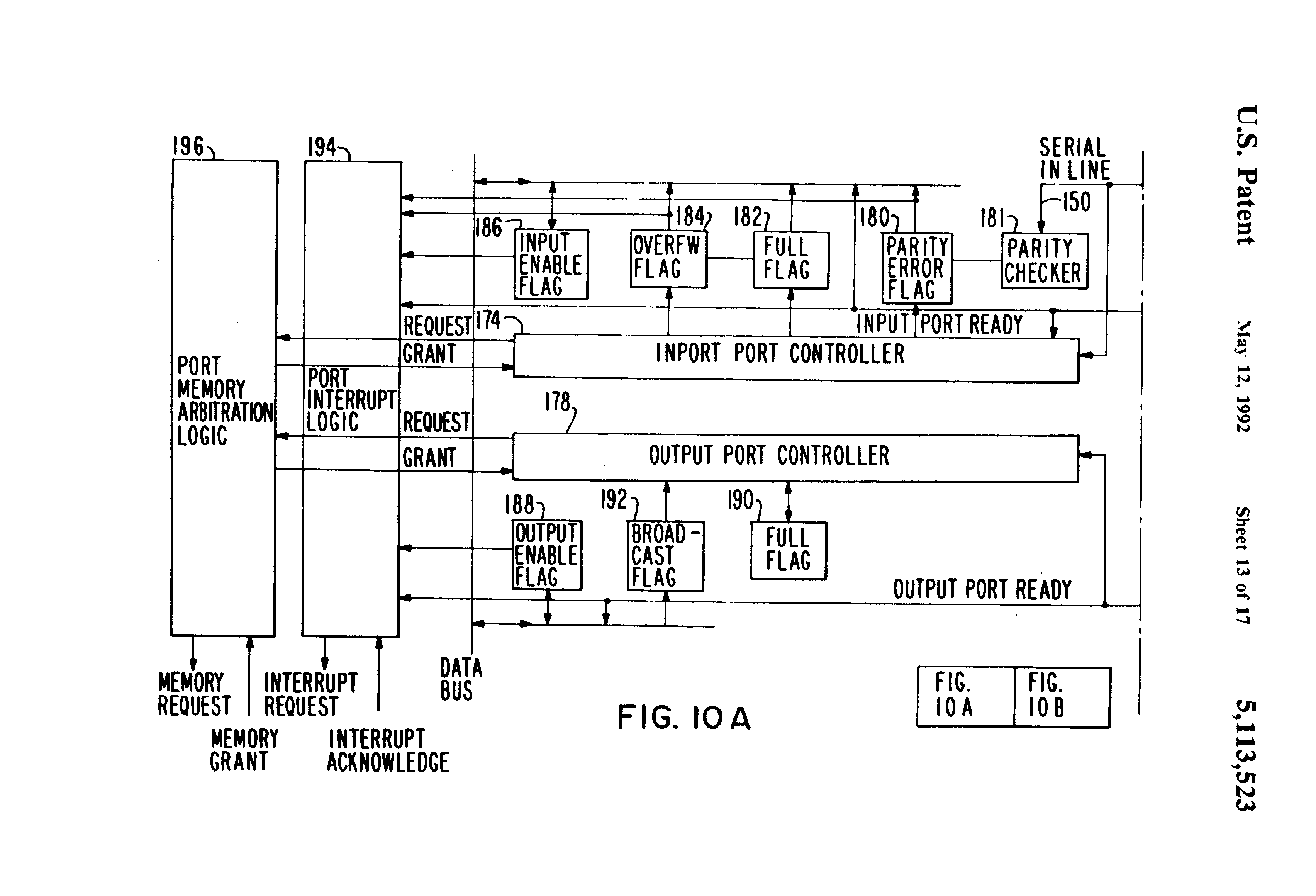
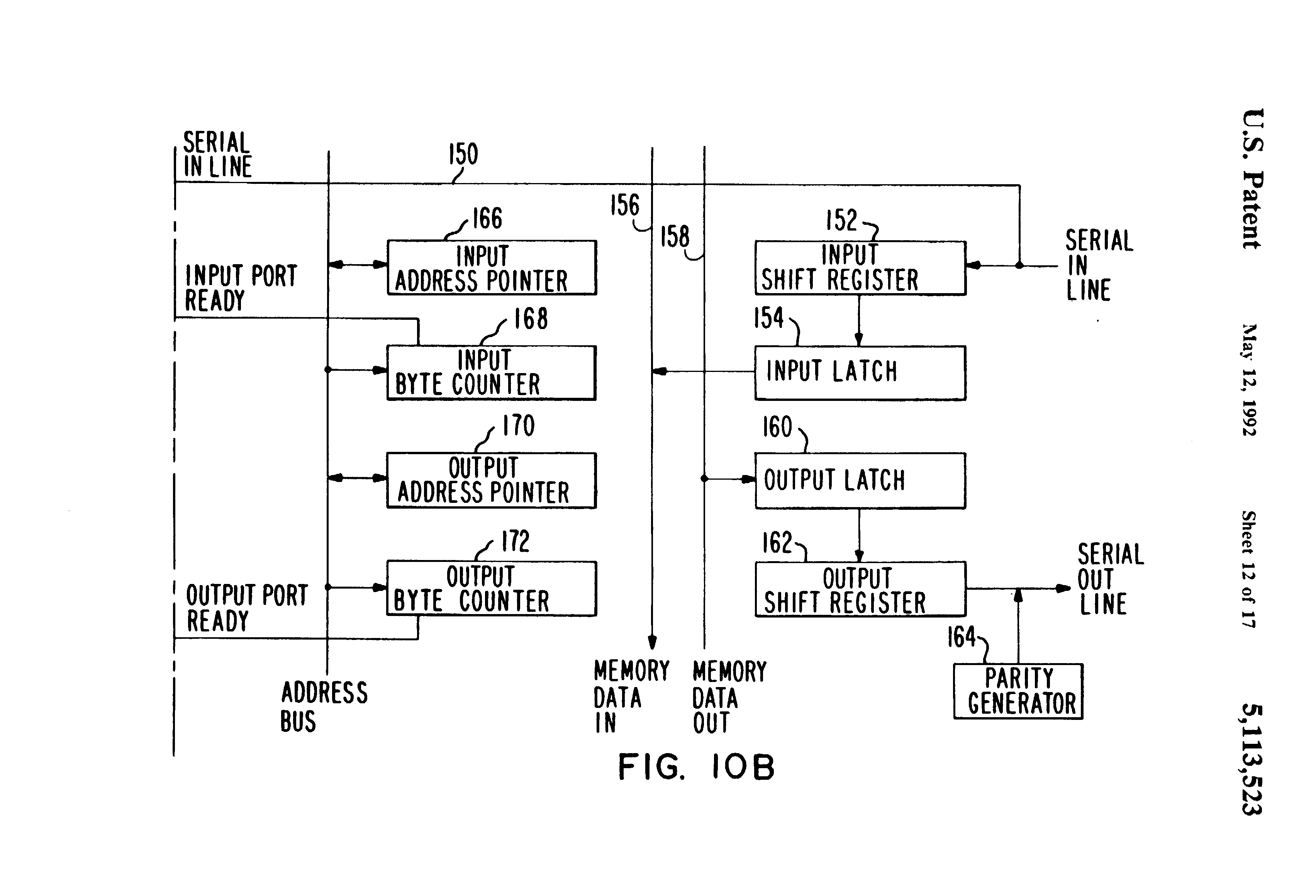
Fig 10a and Fig 10b together is a detailed block diagram of the one of the eleven serial I/O ports shown in FIG. 5;
{kind=link}
{kind=link}
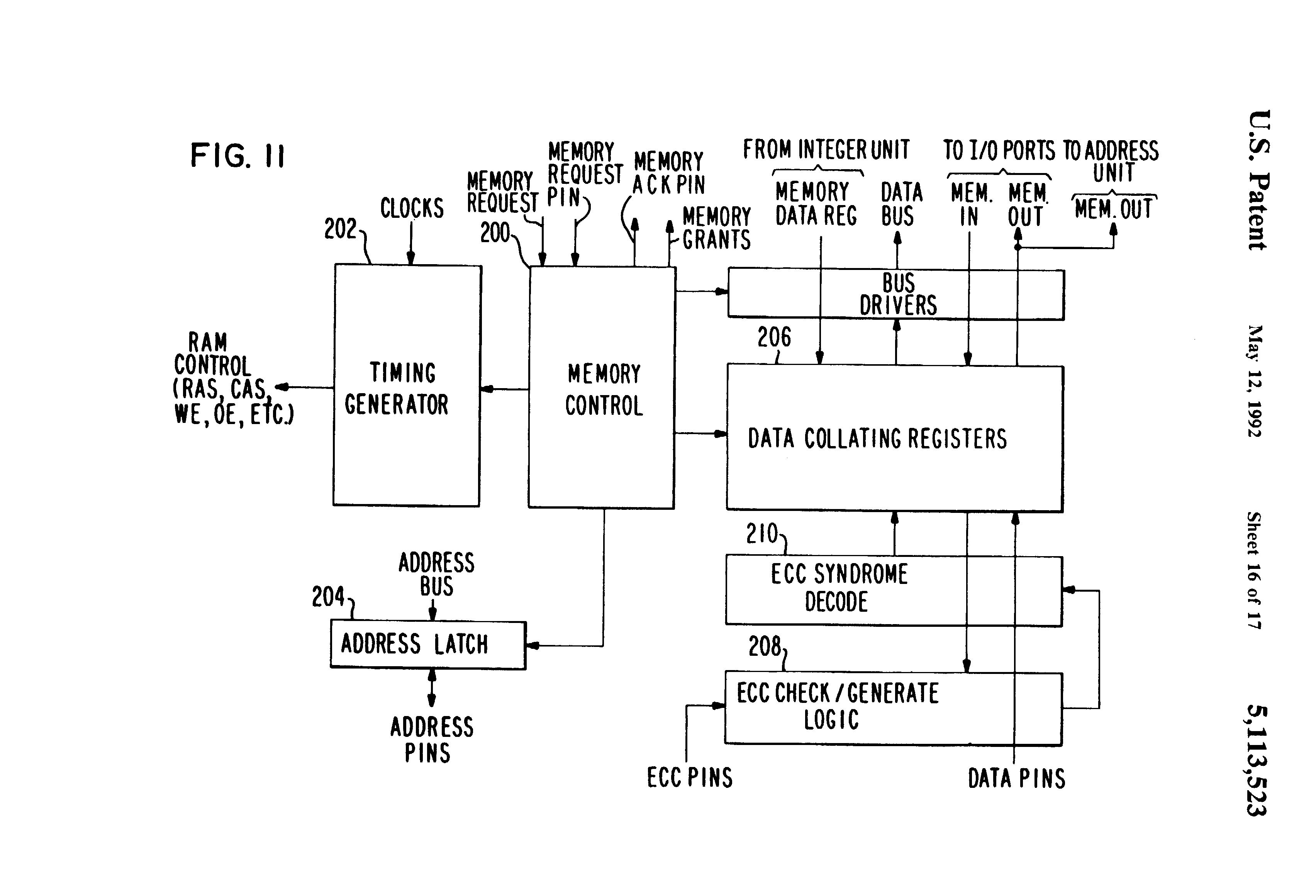
Fig 11 is a detailed block diagram of the memory interface logic shown in FIG. 5;
{kind=link}
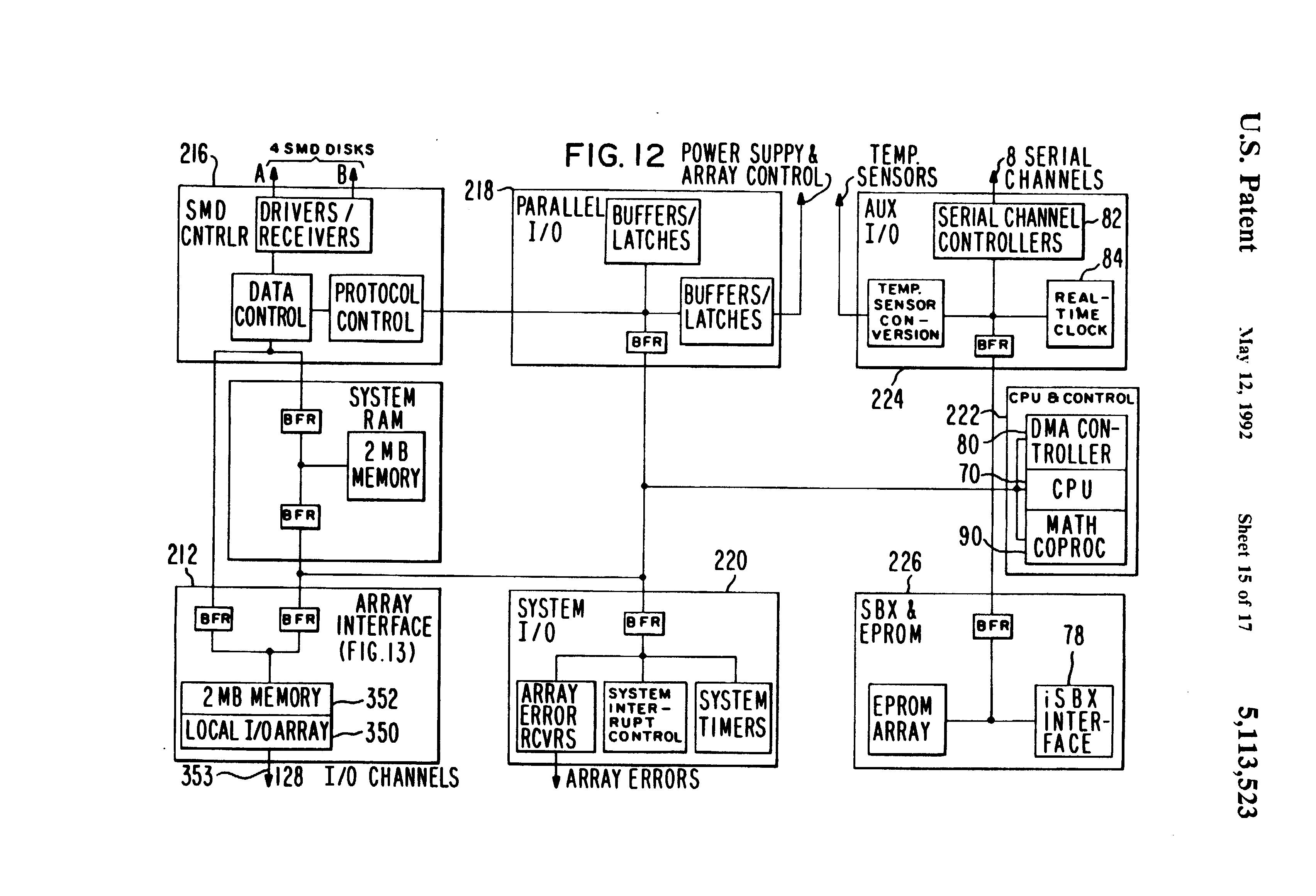
Fig 12 is a detailed block diagram of the system control board shown in FIG. 1;
{kind=link}
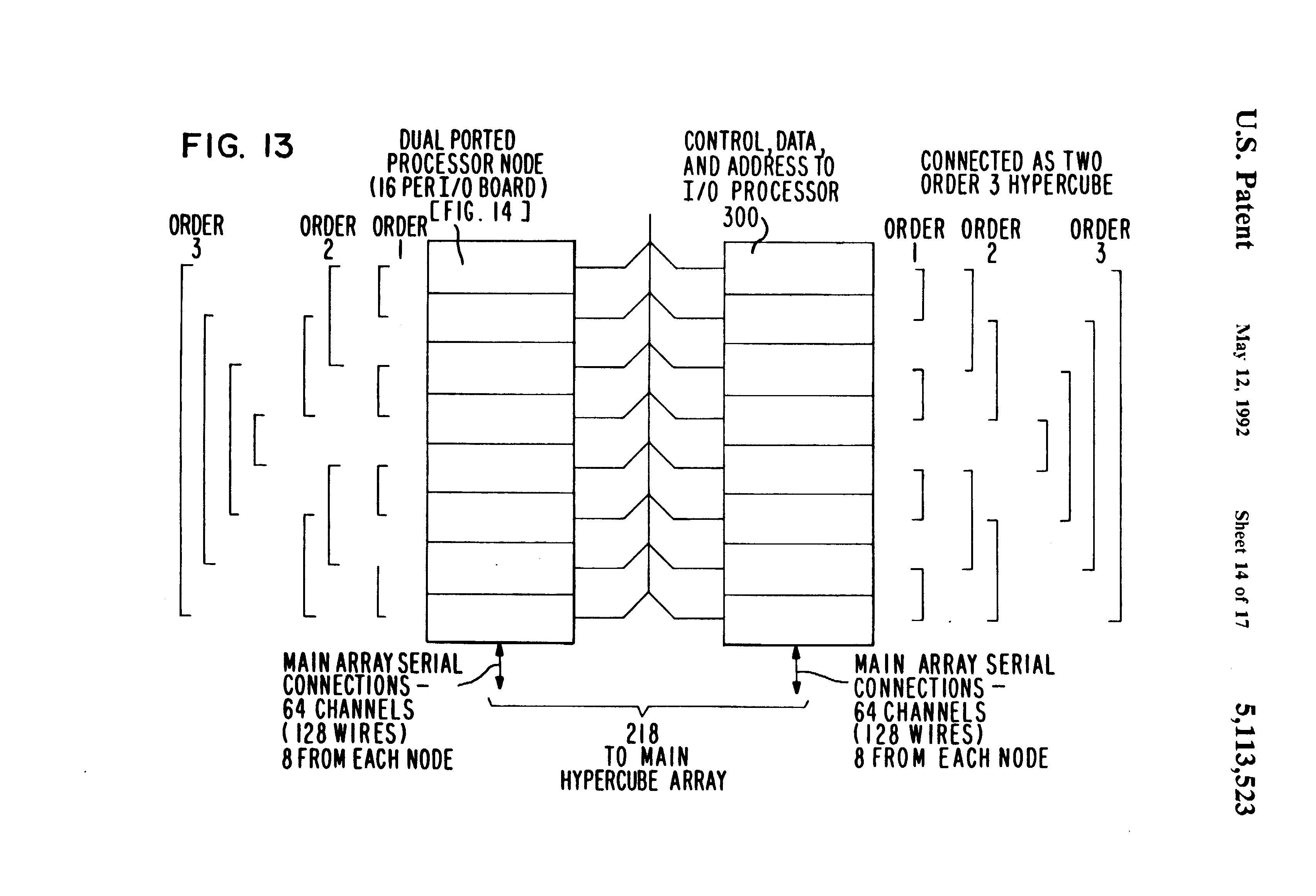
Fig 13 is a detailed block diagram of the dual-ported processing nodes and serial communications interconnect on the system control board array interface shown in FIG. 12; and,
{kind=link}
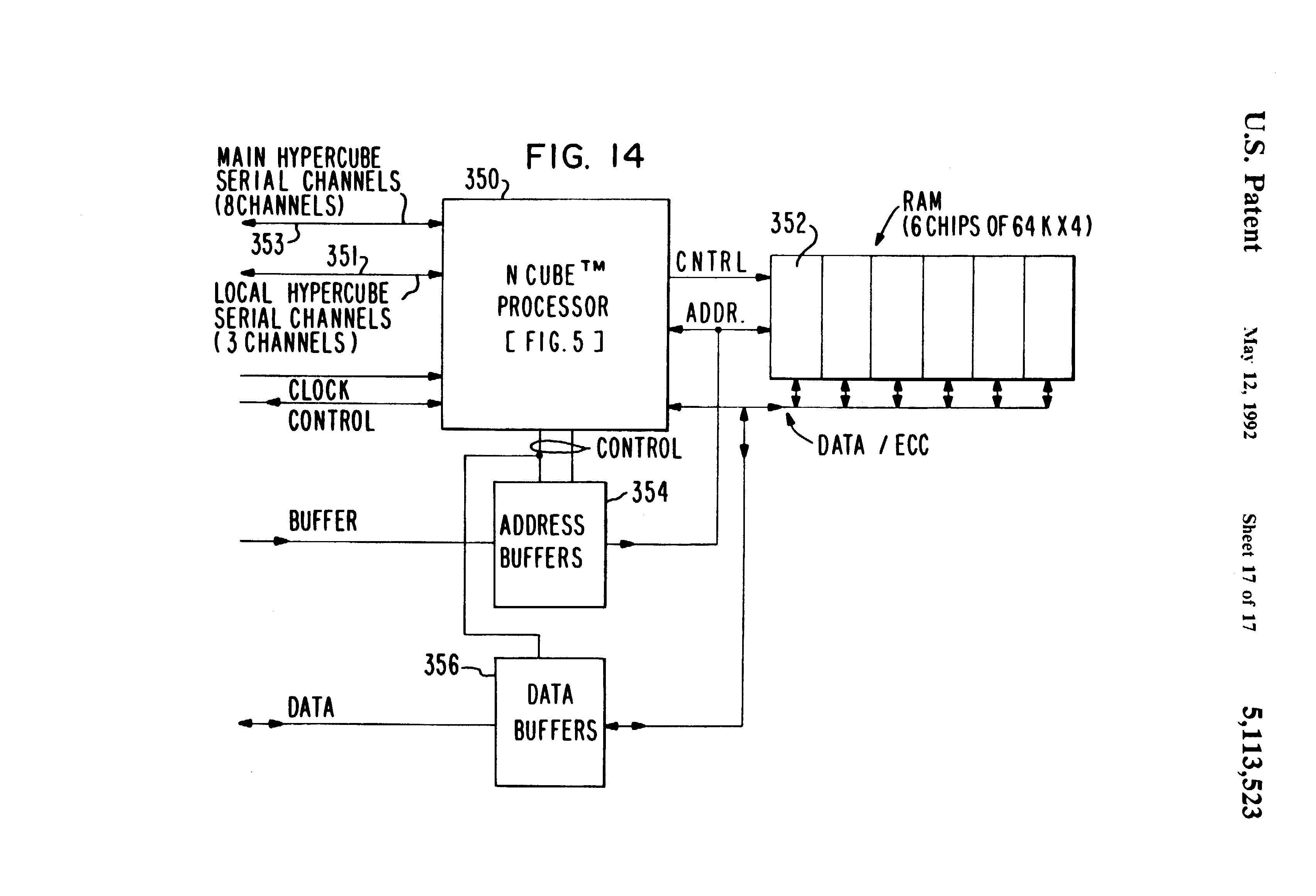
Fig 14 is a detailed block diagram of a single dual ported-processing node of the system control board interface shown in FIG. 13.
{kind=link}